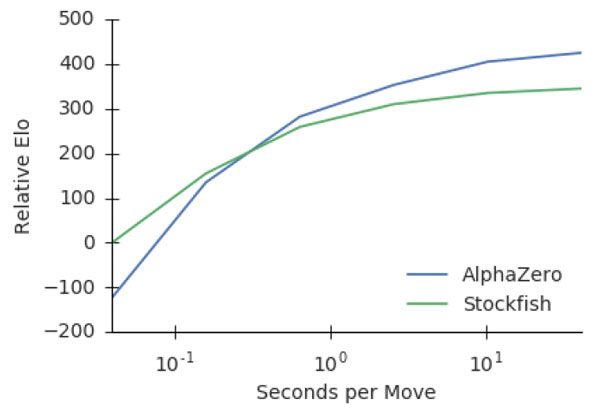
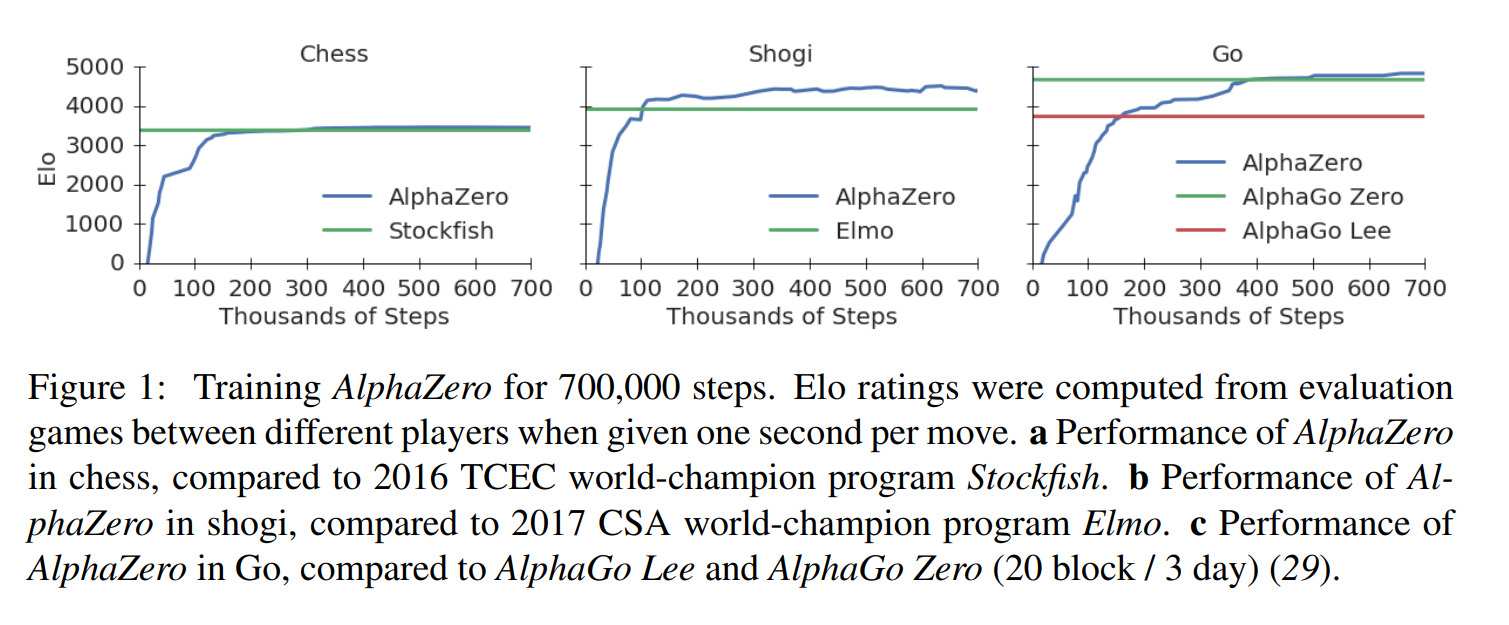
Training AlphaZero for 700,000 steps. Elo ratings were computed
Por um escritor misterioso
Descrição

AlphaZero really is that good

Simple Alpha Zero
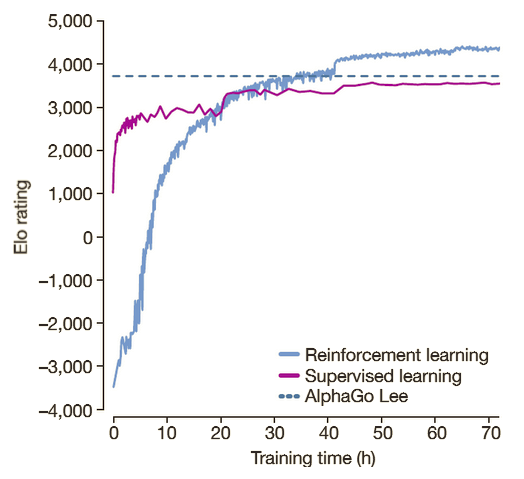
AlphaGo Zero Explained

Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
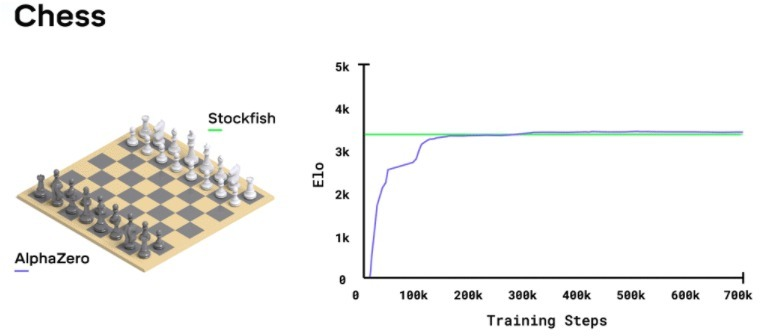
Checkmate for Traditional Chess? - Nekst-Online

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines

AlphaZero: Shedding new light on the grand games of chess, shogi and Go [DM releases followup paper on AlphaZero, +100 shogi games, +100 chess games, and video discussion] : r/reinforcementlearning

In chess, Alpha Zero demolished Stockfish in a controlled set of 100 matches. What do you guys think? : r/baduk
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
de
por adulto (o preço varia de acordo com o tamanho do grupo)